5 Refurbish
Re-make!
不在之前的2-3000行基础上改
Jun 16
Table 1: Triple-H –> GaoXueYa
11:06
- 他们不接受 三高。 解决: Triple-H –> each Metabolic disease
回归策略:
A. Response: only all 4 ME, not Triple-H
SanGao: strata. regression of ME to lifestyle variables by stratum
add plots
Loading Packages:
Dataset import:
#file.choose()Raw <- read_excel("/Users/xue/Desktop/Exquisite/MEData/rawData.xlsx")Survey coding specifications: under ME folder
5.1 Raw Data Exploration
#View(Raw)原数据有很多_open.开放选项。n ot informative。 暂时不考虑 处理方式:select(!ends_with("open"))
#glimpse(Raw)疾病变量 (GaoXueYa) 等在数据中是数值变量
glimpse(), gaze() 发现,性别,年龄身高体重均误为字符。
清洗解决:在原excel改错误的数据格式。 做法添加正确列: C2 = value(B2)
创造 Raw_clean: 已直接在excel 里加上了 Age, Height, Weight, 所以无需在R里tidy,直接select去掉年龄,身高,体重这些旧的错误的字符变量。另 外,去掉开放问题
Raw_clean: New Dataset Created!
再检查:
gaze(Raw_clean)————————————————————————————————————————————————
name levels stats
————————————————————————————————————————————————
性别 Mean ± SD 1.7 ± 0.5
Age Mean ± SD 28.9 ± 9.1
Height Mean ± SD 167.1 ± 8.7
Weight Mean ± SD 71.5 ± 29.1
Race 35 unique values
Occupation Mean ± SD 3.5 ± 2.5
Living Mean ± SD 2.5 ± 0.7
Education Mean ± SD 2.9 ± 0.5
Monthly_Income Mean ± SD 2.1 ± 0.9
Exercise Mean ± SD 2.2 ± 1.1
Sleeping Mean ± SD 5.1 ± 1.2
Smoking Mean ± SD 4.5 ± 0.8
Drinking Mean ± SD 3.8 ± 0.7
ME_Attention Mean ± SD 20.2 ± 3.3
ME_SatietyCue Mean ± SD 19.4 ± 3.5
ME_Awareness Mean ± SD 10.2 ± 3.5
ME_Distraction Mean ± SD 13.5 ± 3.9
GaoXueYa Mean ± SD 0.1 ± 0.2
XueZhiYiChang Mean ± SD 0.0 ± 0.2
GaoXueTang Mean ± SD 0.0 ± 0.2
Cancer Mean ± SD 0.0 ± 0.1
ManXingFeiBu Mean ± SD 0.0 ± 0.1
GanZang Mean ± SD 0.0 ± 0.1
XinZangBing Mean ± SD 0.0 ± 0.1
Stroke Mean ± SD 0.0 ± 0.1
Kidney Mean ± SD 0.0 ± 0.1
WeiXiaoHuaDao Mean ± SD 0.1 ± 0.2
QingGanJingShen Mean ± SD 0.0 ± 0.1
JiYi Mean ± SD 0.0 ± 0.1
GuanJieYan Mean ± SD 0.0 ± 0.1
Asthma Mean ± SD 0.0 ± 0.0
YaJianKang Mean ± SD 0.0 ± 0.2
YaLi Mean ± SD 19.3 ± 11.6
JiaoLv Mean ± SD 17.7 ± 11.8
YiYu Mean ± SD 17.7 ± 12.4
————————————————————————————————————————————————数据依然脏: 1.性别 被错误视为了数值变量 2.各疾病,状态 被视为了数值变量
1.性别 wrong type. Create Gender
Raw_clean: New Dataset Updated!
2.疾病变量 wrong type, 需变成factor: as.factor()
暂时先考虑 3个关心的新陈代谢综合症 其它病也需要
Raw_clean: New Dataset Updated!
Re-examine
#gaze(Raw_clean)当然,其他condition/status如果需要考虑,也需要 mutate_at(c('cond1','cond2'),as.factor)
6 Exploratory Data Analysis
6.1 Missing Data: missingVis
对干净数据 Raw_clean 进行检查。 我自己的包 xue 不用额外载入 xue:: 即可
xue::missingVis(Raw_clean)
无缺失。
6.2 Descriptive Analysis
autoReg::gaze.
1. 不分组,全体描述性统计量
gaze(data = Raw_clean)—————————————————————————————————————————————————
name levels stats
—————————————————————————————————————————————————
Gender Female 878 (65.8%)
Male 457 (34.2%)
Age Mean ± SD 28.9 ± 9.1
Height Mean ± SD 167.1 ± 8.7
Weight Mean ± SD 71.5 ± 29.1
Race 35 unique values
Occupation Mean ± SD 3.5 ± 2.5
Living Mean ± SD 2.5 ± 0.7
Education 1 25 (1.9%)
2 159 (11.9%)
3 1049 (78.6%)
4 102 (7.6%)
Monthly_Income 1 411 (30.8%)
2 453 (33.9%)
3 403 (30.2%)
4 68 (5.1%)
Exercise 1 415 (31.1%)
2 413 (30.9%)
3 341 (25.5%)
4 126 (9.4%)
5 40 (3.0%)
Sleeping 3 170 (12.7%)
4 239 (17.9%)
5 429 (32.1%)
6 343 (25.7%)
7 154 (11.5%)
Smoking 4 917 (68.7%)
5 227 (17.0%)
6 129 (9.7%)
7 62 (4.6%)
Drinking 3 563 (42.2%)
4 553 (41.4%)
5 208 (15.6%)
6 11 (0.8%)
ME_Attention Mean ± SD 20.2 ± 3.3
ME_SatietyCue Mean ± SD 19.4 ± 3.5
ME_Awareness Mean ± SD 10.2 ± 3.5
ME_Distraction Mean ± SD 13.5 ± 3.9
GaoXueYa 0 1268 (95.0%)
1 67 (5.0%)
XueZhiYiChang 0 1273 (95.4%)
1 62 (4.6%)
GaoXueTang 0 1297 (97.2%)
1 38 (2.8%)
Cancer Mean ± SD 0.0 ± 0.1
ManXingFeiBu Mean ± SD 0.0 ± 0.1
GanZang Mean ± SD 0.0 ± 0.1
XinZangBing Mean ± SD 0.0 ± 0.1
Stroke Mean ± SD 0.0 ± 0.1
Kidney Mean ± SD 0.0 ± 0.1
WeiXiaoHuaDao Mean ± SD 0.1 ± 0.2
QingGanJingShen Mean ± SD 0.0 ± 0.1
JiYi Mean ± SD 0.0 ± 0.1
GuanJieYan Mean ± SD 0.0 ± 0.1
Asthma Mean ± SD 0.0 ± 0.0
YaJianKang Mean ± SD 0.0 ± 0.2
YaLi Mean ± SD 19.3 ± 11.6
JiaoLv Mean ± SD 17.7 ± 11.8
YiYu Mean ± SD 17.7 ± 12.4
—————————————————————————————————————————————————2. 分组,描述性 + 2组差异检验
注意!不采用的结果!看解释
name |
levels |
0 (N=1268) |
1 (N=67) |
p |
|---|---|---|---|---|
Gender |
Female |
849 (67%) |
29 (43.3%) |
<.001 |
Male |
419 (33%) |
38 (56.7%) |
||
Age |
Mean ± SD |
28.5 ± 8.8 |
37.1 ± 11.1 |
<.001 |
Height |
Mean ± SD |
167.0 ± 8.7 |
169.1 ± 7.9 |
.049 |
Weight |
Mean ± SD |
71.1 ± 29.1 |
78.8 ± 28.6 |
.036 |
Occupation |
Mean ± SD |
3.5 ± 2.5 |
3.9 ± 1.8 |
.051 |
Living |
Mean ± SD |
2.5 ± 0.7 |
2.6 ± 0.6 |
.136 |
Education |
1 |
24 (1.9%) |
1 (1.5%) |
.048 |
2 |
144 (11.4%) |
15 (22.4%) |
||
3 |
1001 (78.9%) |
48 (71.6%) |
||
4 |
99 (7.8%) |
3 (4.5%) |
||
Monthly_Income |
1 |
403 (31.8%) |
8 (11.9%) |
.001 |
2 |
423 (33.4%) |
30 (44.8%) |
||
3 |
375 (29.6%) |
28 (41.8%) |
||
4 |
67 (5.3%) |
1 (1.5%) |
||
Exercise |
1 |
408 (32.2%) |
7 (10.4%) |
.003 |
2 |
390 (30.8%) |
23 (34.3%) |
||
3 |
315 (24.8%) |
26 (38.8%) |
||
4 |
118 (9.3%) |
8 (11.9%) |
||
5 |
37 (2.9%) |
3 (4.5%) |
||
Sleeping |
3 |
163 (12.9%) |
7 (10.4%) |
.438 |
4 |
228 (18%) |
11 (16.4%) |
||
5 |
402 (31.7%) |
27 (40.3%) |
||
6 |
325 (25.6%) |
18 (26.9%) |
||
7 |
150 (11.8%) |
4 (6%) |
||
Smoking |
4 |
893 (70.4%) |
24 (35.8%) |
<.001 |
5 |
208 (16.4%) |
19 (28.4%) |
||
6 |
112 (8.8%) |
17 (25.4%) |
||
7 |
55 (4.3%) |
7 (10.4%) |
||
Drinking |
3 |
550 (43.4%) |
13 (19.4%) |
<.001 |
4 |
528 (41.6%) |
25 (37.3%) |
||
5 |
180 (14.2%) |
28 (41.8%) |
||
6 |
10 (0.8%) |
1 (1.5%) |
||
ME_Attention |
Mean ± SD |
20.2 ± 3.3 |
19.5 ± 3.4 |
.095 |
ME_SatietyCue |
Mean ± SD |
19.4 ± 3.5 |
19.5 ± 3.3 |
.861 |
ME_Awareness |
Mean ± SD |
10.2 ± 3.6 |
10.5 ± 3.4 |
.425 |
ME_Distraction |
Mean ± SD |
13.5 ± 3.9 |
14.0 ± 4.1 |
.348 |
XueZhiYiChang |
0 |
1222 (96.4%) |
51 (76.1%) |
<.001 |
1 |
46 (3.6%) |
16 (23.9%) |
||
GaoXueTang |
0 |
1236 (97.5%) |
61 (91%) |
.007 |
1 |
32 (2.5%) |
6 (9%) |
||
Cancer |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.916 |
ManXingFeiBu |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.882 |
GanZang |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.821 |
XinZangBing |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.121 |
Stroke |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.208 |
Kidney |
Mean ± SD |
0.0 ± 0.1 |
0.1 ± 0.2 |
.072 |
WeiXiaoHuaDao |
Mean ± SD |
0.1 ± 0.2 |
0.0 ± 0.2 |
.330 |
QingGanJingShen |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.0 |
<.001 |
JiYi |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.357 |
GuanJieYan |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.419 |
Asthma |
Mean ± SD |
0.0 ± 0.0 |
0.0 ± 0.0 |
.157 |
YaJianKang |
Mean ± SD |
0.0 ± 0.2 |
0.0 ± 0.2 |
.633 |
YaLi |
Mean ± SD |
19.1 ± 11.6 |
22.9 ± 10.6 |
.009 |
JiaoLv |
Mean ± SD |
17.5 ± 11.7 |
21.5 ± 11.6 |
.007 |
YiYu |
Mean ± SD |
17.5 ± 12.4 |
21.9 ± 12.1 |
.005 |
暂时不考虑Race。 处理方式: select(!Race))
Compare 高血压0 vs. 高血压1,on 4 scales, 只有 Attention 合理,其余结果都不好。 其中 Satiety 2组相等 不好很正常:题目难懂 没有实际情境 Awareness, Distraction 更接近反向差异:
6.2.1 原因: 调查问卷反向设计
Raw_clean_modify
策略:没有任何三高的人(Status = 0) & 答了低分,用18减
mutate SanGaoScore
Raw_clean <-
Raw_clean |>
mutate(SanGaoScore = as.numeric(GaoXueYa) + as.numeric(GaoXueTang) + as.numeric(XueZhiYiChang) - 3, .after = ME_Distraction)Raw_clean_modify: New Dataset Created!
Raw_clean_modify <-
Raw_clean |>
mutate(ME_New_Awareness = case_when(
# 没三高 低分 变高
# 没三高 高分 不变
# 有三高 低分 不变
# 有三高 高分 不变?或变低
SanGaoScore == 0 & ME_Awareness <= 7 ~ 18 - ME_Awareness,
SanGaoScore == 0 & ME_Awareness > 7 ~ ME_Awareness,
SanGaoScore > 0 & ME_Awareness <= 7 ~ ME_Awareness,
SanGaoScore > 0 & ME_Awareness > 7 ~ ME_Awareness
),
.after = ME_Awareness) |>
mutate(ME_New_Distraction = case_when(
SanGaoScore == 0 & ME_Distraction <= 8 ~ 24 - ME_Distraction,
SanGaoScore == 0 & ME_Distraction > 8 ~ ME_Distraction,
SanGaoScore > 0 & ME_Distraction <= 8 ~ ME_Distraction,
SanGaoScore > 0 & ME_Distraction > 8 ~ ME_Distraction
),
.after = ME_Distraction) 7 新 描述性统计 工作流:
7.0.1 工作流: Two-Group Comparison Workflow
有/无 高血压 对比
name |
levels |
0 (N=1268) |
1 (N=67) |
p |
|---|---|---|---|---|
Gender |
Female |
849 (67%) |
29 (43.3%) |
<.001 |
Male |
419 (33%) |
38 (56.7%) |
||
Age |
Mean ± SD |
28.5 ± 8.8 |
37.1 ± 11.1 |
<.001 |
Height |
Mean ± SD |
167.0 ± 8.7 |
169.1 ± 7.9 |
.049 |
Weight |
Mean ± SD |
71.1 ± 29.1 |
78.8 ± 28.6 |
.036 |
Occupation |
Mean ± SD |
3.5 ± 2.5 |
3.9 ± 1.8 |
.051 |
Living |
Mean ± SD |
2.5 ± 0.7 |
2.6 ± 0.6 |
.136 |
Education |
1 |
24 (1.9%) |
1 (1.5%) |
.048 |
2 |
144 (11.4%) |
15 (22.4%) |
||
3 |
1001 (78.9%) |
48 (71.6%) |
||
4 |
99 (7.8%) |
3 (4.5%) |
||
Monthly_Income |
1 |
403 (31.8%) |
8 (11.9%) |
.001 |
2 |
423 (33.4%) |
30 (44.8%) |
||
3 |
375 (29.6%) |
28 (41.8%) |
||
4 |
67 (5.3%) |
1 (1.5%) |
||
Exercise |
1 |
408 (32.2%) |
7 (10.4%) |
.003 |
2 |
390 (30.8%) |
23 (34.3%) |
||
3 |
315 (24.8%) |
26 (38.8%) |
||
4 |
118 (9.3%) |
8 (11.9%) |
||
5 |
37 (2.9%) |
3 (4.5%) |
||
Sleeping |
3 |
163 (12.9%) |
7 (10.4%) |
.438 |
4 |
228 (18%) |
11 (16.4%) |
||
5 |
402 (31.7%) |
27 (40.3%) |
||
6 |
325 (25.6%) |
18 (26.9%) |
||
7 |
150 (11.8%) |
4 (6%) |
||
Smoking |
4 |
893 (70.4%) |
24 (35.8%) |
<.001 |
5 |
208 (16.4%) |
19 (28.4%) |
||
6 |
112 (8.8%) |
17 (25.4%) |
||
7 |
55 (4.3%) |
7 (10.4%) |
||
Drinking |
3 |
550 (43.4%) |
13 (19.4%) |
<.001 |
4 |
528 (41.6%) |
25 (37.3%) |
||
5 |
180 (14.2%) |
28 (41.8%) |
||
6 |
10 (0.8%) |
1 (1.5%) |
||
ME_Attention |
Mean ± SD |
20.2 ± 3.3 |
19.5 ± 3.4 |
.095 |
ME_SatietyCue |
Mean ± SD |
19.4 ± 3.5 |
19.5 ± 3.3 |
.861 |
ME_Awareness |
Mean ± SD |
10.2 ± 3.6 |
10.5 ± 3.4 |
.425 |
ME_New_Awareness |
Mean ± SD |
12.1 ± 2.1 |
10.5 ± 3.4 |
<.001 |
ME_Distraction |
Mean ± SD |
13.5 ± 3.9 |
14.0 ± 4.1 |
.348 |
ME_New_Distraction |
Mean ± SD |
14.9 ± 3.0 |
14.0 ± 4.1 |
.068 |
SanGaoScore |
Mean ± SD |
0.1 ± 0.3 |
1.3 ± 0.6 |
<.001 |
XueZhiYiChang |
0 |
1222 (96.4%) |
51 (76.1%) |
<.001 |
1 |
46 (3.6%) |
16 (23.9%) |
||
GaoXueTang |
0 |
1236 (97.5%) |
61 (91%) |
.007 |
1 |
32 (2.5%) |
6 (9%) |
||
Cancer |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.916 |
ManXingFeiBu |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.882 |
GanZang |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.821 |
XinZangBing |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.121 |
Stroke |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.208 |
Kidney |
Mean ± SD |
0.0 ± 0.1 |
0.1 ± 0.2 |
.072 |
WeiXiaoHuaDao |
Mean ± SD |
0.1 ± 0.2 |
0.0 ± 0.2 |
.330 |
QingGanJingShen |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.0 |
<.001 |
JiYi |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.357 |
GuanJieYan |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.419 |
Asthma |
Mean ± SD |
0.0 ± 0.0 |
0.0 ± 0.0 |
.157 |
YaJianKang |
Mean ± SD |
0.0 ± 0.2 |
0.0 ± 0.2 |
.633 |
YaLi |
Mean ± SD |
19.1 ± 11.6 |
22.9 ± 10.6 |
.009 |
JiaoLv |
Mean ± SD |
17.5 ± 11.7 |
21.5 ± 11.6 |
.007 |
YiYu |
Mean ± SD |
17.5 ± 12.4 |
21.9 ± 12.1 |
.005 |
压力 抑郁 焦虑 均显著。
工作流:
gaze(GaoXueYa~., data = Raw_clean_modify |> select(!Race)) |>
myft() |>
table2docx(vanilla = TRUE)Exported table as Report.docx表格modify: 0,1 –> 无高血压 高血压 ,送通义千问
有/无 血脂异常 对比
name |
levels |
0 (N=1273) |
1 (N=62) |
p |
|---|---|---|---|---|
Gender |
Female |
847 (66.5%) |
31 (50%) |
.011 |
Male |
426 (33.5%) |
31 (50%) |
||
Age |
Mean ± SD |
28.6 ± 8.8 |
35.9 ± 12.8 |
<.001 |
Height |
Mean ± SD |
167.0 ± 8.6 |
169.0 ± 9.0 |
.075 |
Weight |
Mean ± SD |
71.3 ± 29.0 |
76.4 ± 29.6 |
.177 |
Occupation |
Mean ± SD |
3.5 ± 2.5 |
4.3 ± 2.4 |
.012 |
Living |
Mean ± SD |
2.5 ± 0.7 |
2.5 ± 0.7 |
.965 |
Education |
1 |
16 (1.3%) |
9 (14.5%) |
<.001 |
2 |
149 (11.7%) |
10 (16.1%) |
||
3 |
1012 (79.5%) |
37 (59.7%) |
||
4 |
96 (7.5%) |
6 (9.7%) |
||
Monthly_Income |
1 |
404 (31.7%) |
7 (11.3%) |
.003 |
2 |
431 (33.9%) |
22 (35.5%) |
||
3 |
375 (29.5%) |
28 (45.2%) |
||
4 |
63 (4.9%) |
5 (8.1%) |
||
Exercise |
1 |
408 (32.1%) |
7 (11.3%) |
.006 |
2 |
389 (30.6%) |
24 (38.7%) |
||
3 |
323 (25.4%) |
18 (29%) |
||
4 |
115 (9%) |
11 (17.7%) |
||
5 |
38 (3%) |
2 (3.2%) |
||
Sleeping |
3 |
164 (12.9%) |
6 (9.7%) |
.631 |
4 |
226 (17.8%) |
13 (21%) |
||
5 |
407 (32%) |
22 (35.5%) |
||
6 |
326 (25.6%) |
17 (27.4%) |
||
7 |
150 (11.8%) |
4 (6.5%) |
||
Smoking |
4 |
889 (69.8%) |
28 (45.2%) |
<.001 |
5 |
209 (16.4%) |
18 (29%) |
||
6 |
120 (9.4%) |
9 (14.5%) |
||
7 |
55 (4.3%) |
7 (11.3%) |
||
Drinking |
3 |
547 (43%) |
16 (25.8%) |
.007 |
4 |
526 (41.3%) |
27 (43.5%) |
||
5 |
190 (14.9%) |
18 (29%) |
||
6 |
10 (0.8%) |
1 (1.6%) |
||
ME_Attention |
Mean ± SD |
20.2 ± 3.2 |
18.9 ± 3.8 |
.002 |
ME_SatietyCue |
Mean ± SD |
19.4 ± 3.5 |
19.5 ± 3.5 |
.910 |
ME_Awareness |
Mean ± SD |
10.1 ± 3.6 |
11.2 ± 2.7 |
.004 |
ME_New_Awareness |
Mean ± SD |
12.1 ± 2.2 |
11.2 ± 2.7 |
.015 |
ME_Distraction |
Mean ± SD |
13.4 ± 3.9 |
15.3 ± 3.2 |
<.001 |
ME_New_Distraction |
Mean ± SD |
14.8 ± 3.0 |
15.3 ± 3.2 |
.225 |
SanGaoScore |
Mean ± SD |
0.1 ± 0.3 |
1.4 ± 0.6 |
<.001 |
GaoXueYa |
0 |
1222 (96%) |
46 (74.2%) |
<.001 |
1 |
51 (4%) |
16 (25.8%) |
||
GaoXueTang |
0 |
1242 (97.6%) |
55 (88.7%) |
<.001 |
1 |
31 (2.4%) |
7 (11.3%) |
||
Cancer |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.190 |
ManXingFeiBu |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.242 |
GanZang |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.355 |
XinZangBing |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.2 |
.243 |
Stroke |
Mean ± SD |
0.0 ± 0.0 |
0.0 ± 0.2 |
.099 |
Kidney |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.648 |
WeiXiaoHuaDao |
Mean ± SD |
0.0 ± 0.2 |
0.1 ± 0.3 |
.370 |
QingGanJingShen |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.1 |
.648 |
JiYi |
Mean ± SD |
0.0 ± 0.1 |
0.0 ± 0.0 |
<.001 |
GuanJieYan |
Mean ± SD |
0.0 ± 0.1 |
0.1 ± 0.2 |
.095 |
Asthma |
Mean ± SD |
0.0 ± 0.0 |
0.0 ± 0.0 |
.157 |
YaJianKang |
Mean ± SD |
0.0 ± 0.2 |
0.0 ± 0.2 |
.564 |
YaLi |
Mean ± SD |
19.1 ± 11.5 |
22.8 ± 12.0 |
.014 |
JiaoLv |
Mean ± SD |
17.5 ± 11.8 |
22.0 ± 11.2 |
.003 |
YiYu |
Mean ± SD |
17.5 ± 12.4 |
23.1 ± 12.6 |
<.001 |
工作流:
gaze(XueZhiYiChang~., data = Raw_clean_modify |> select(!Race)) |>
myft() |>
table2docx(vanilla = TRUE)Exported table as Report.docx表格modify: 0,1 –> 无高血压 高血压 ,送通义千问
8 回归(需要改)
get_regression_table(GXY_lm)# A tibble: 19 × 7
term estimate std_error statistic p_value lower_ci upper_ci
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 intercept 17.5 4.56 3.84 0 8.33 26.7
2 Gender: Male 1.71 1.11 1.54 0.129 -0.518 3.94
3 Age 0 0.045 0.009 0.993 -0.091 0.091
4 Education: 2 0.001 3.93 0 1 -7.9 7.90
5 Education: 3 1.83 3.86 0.475 0.637 -5.92 9.59
6 Education: 4 1.89 4.71 0.402 0.69 -7.58 11.4
7 Monthly_Income: 2 -0.006 1.79 -0.003 0.997 -3.61 3.60
8 Monthly_Income: 3 1.42 1.88 0.756 0.453 -2.36 5.20
9 Monthly_Income: 4 -1.14 4.11 -0.278 0.782 -9.40 7.12
10 Exercise: 2 0.583 1.80 0.324 0.747 -3.04 4.20
11 Exercise: 3 1.47 1.72 0.856 0.396 -1.99 4.94
12 Exercise: 4 -1.04 2.13 -0.489 0.627 -5.32 3.24
13 Exercise: 5 -3.52 2.66 -1.33 0.191 -8.87 1.82
14 Smoking: 5 -0.797 1.36 -0.585 0.561 -3.54 1.94
15 Smoking: 6 -1.86 1.53 -1.21 0.231 -4.94 1.23
16 Smoking: 7 -1.48 1.91 -0.774 0.443 -5.32 2.36
17 Drinking: 4 -0.473 1.61 -0.294 0.77 -3.71 2.76
18 Drinking: 5 -1.20 1.67 -0.723 0.473 -4.56 2.15
19 Drinking: 6 5.87 4.14 1.42 0.163 -2.46 14.2 get_regression_summaries(GXY_lm)# A tibble: 1 × 9
r_squared adj_r_squared mse rmse sigma statistic p_value df nobs
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.271 -0.003 8.11 2.85 3.36 0.989 0.487 18 67GXY_lm |> select_parameters() |> summary()
Call:
lm(formula = ME_Attention ~ 1, data = filter(Raw_clean_modify,
GaoXueYa == 1))
Residuals:
Min 1Q Median 3Q Max
-14.5075 -2.5075 0.4925 2.4925 5.4925
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19.5075 0.4104 47.53 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.359 on 66 degrees of freedom9 EDA: Visualization
Categorical: Status 高血压,高血糖,血脂异常,性别 - GaoXueYa, GaoXueTang, XueZhiYiChang Gender,
Numeric: ME scales ME_Attention ME_SatietyCue ME_Awareness ME_Distraction
1cat 1num plot: 3*4 = 12 plots
2cat plot (gender + status):
Categorical Variables of Interest: 高血压,高血糖,血脂异常,性别
9.0.1 1 categorical and 1 numerical
9.0.1.1 Boxplot: Mapping a continuous variable to Y, a discrete/categorical variable to X.
GaoXueYa, ME_Attention score is raw, not modified
ggplot(data = Raw_clean_modify,
mapping = aes(x = GaoXueYa, y = ME_Attention)
) +
geom_boxplot()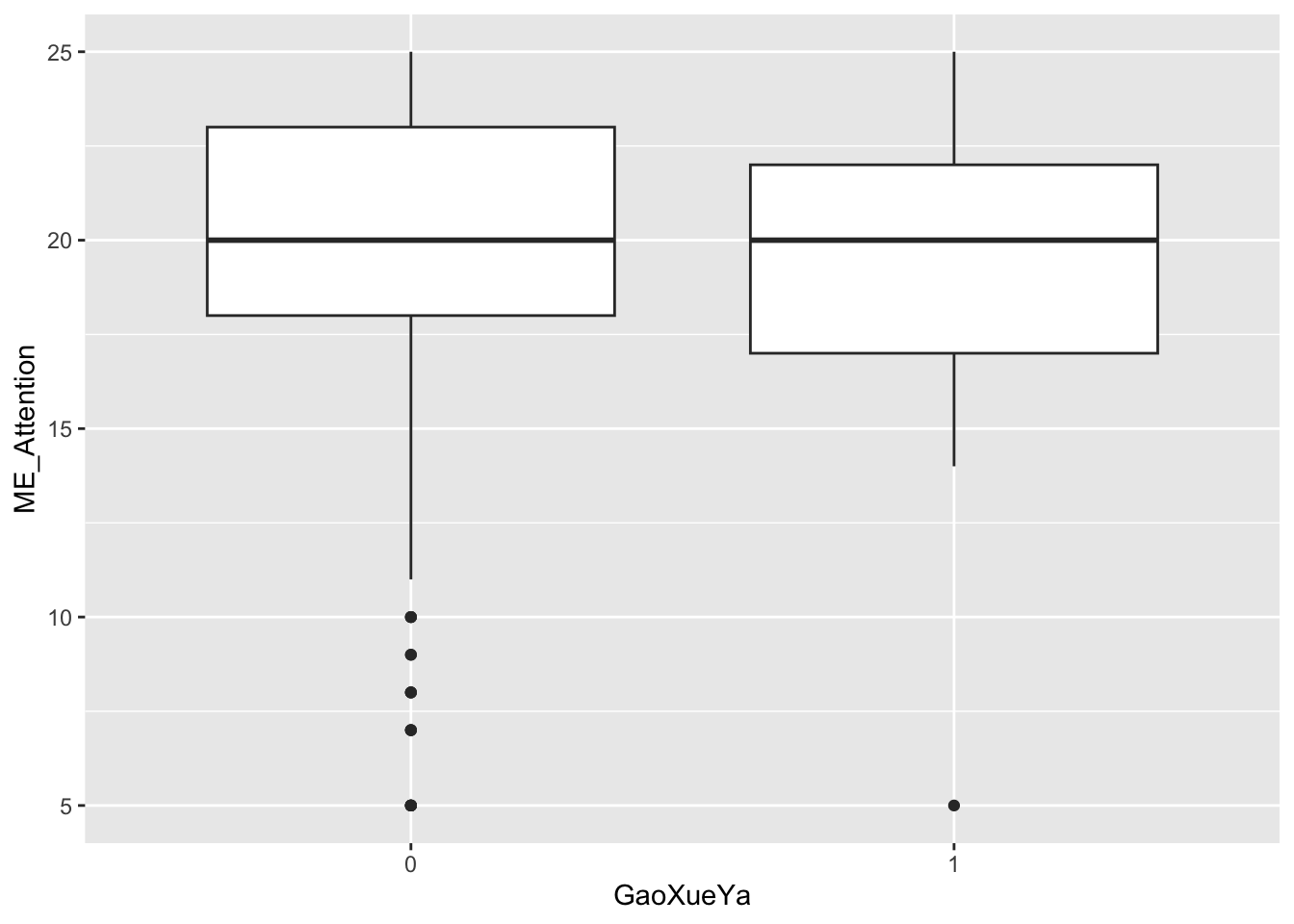
density: x = ME_Attention, color = GaoXueYa
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_Attention, color = GaoXueYa)
) +
geom_density(linewidth = 1)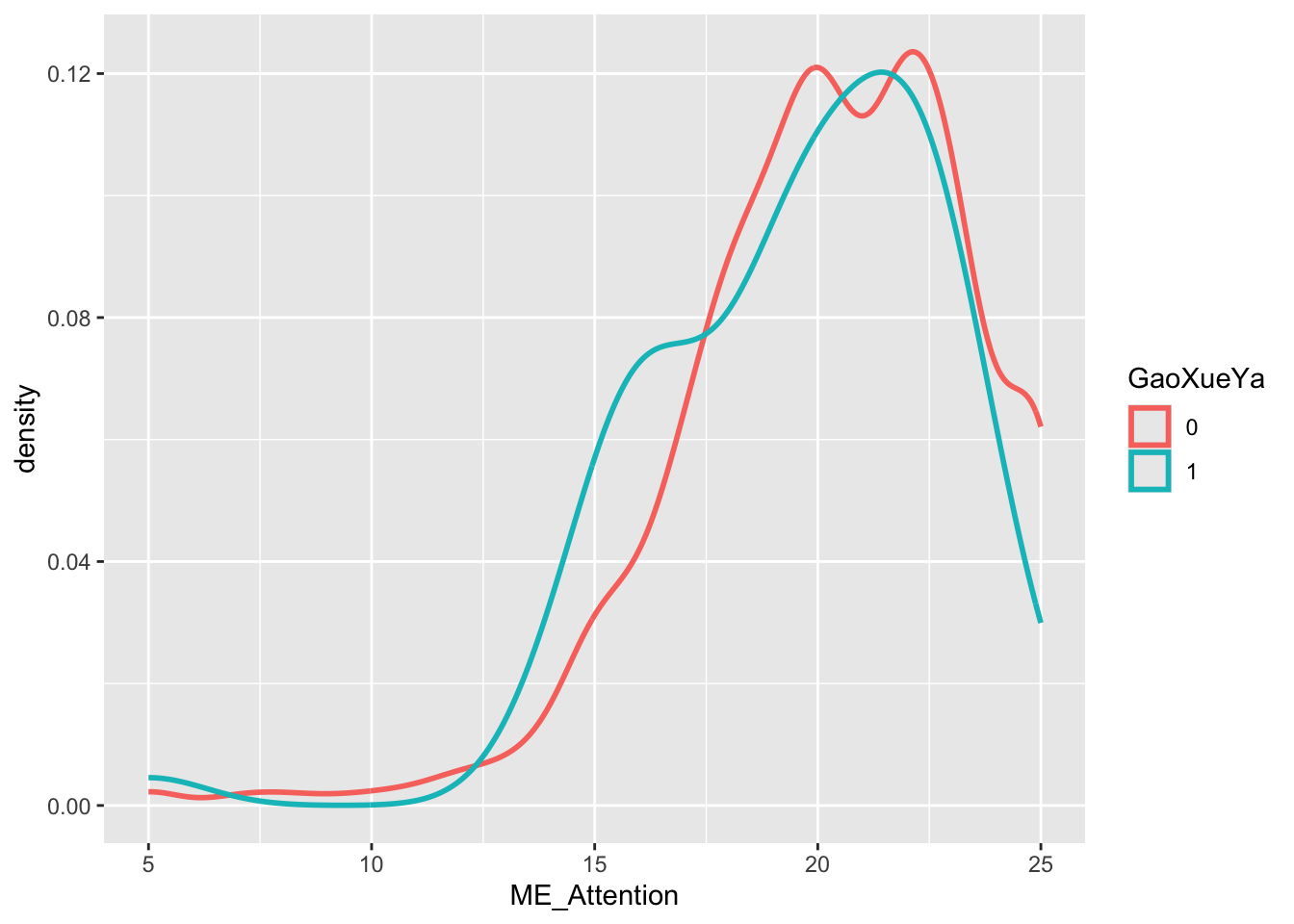
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_Attention, fill = GaoXueYa)
) +
geom_density(linewidth = 1, alpha = 0.6)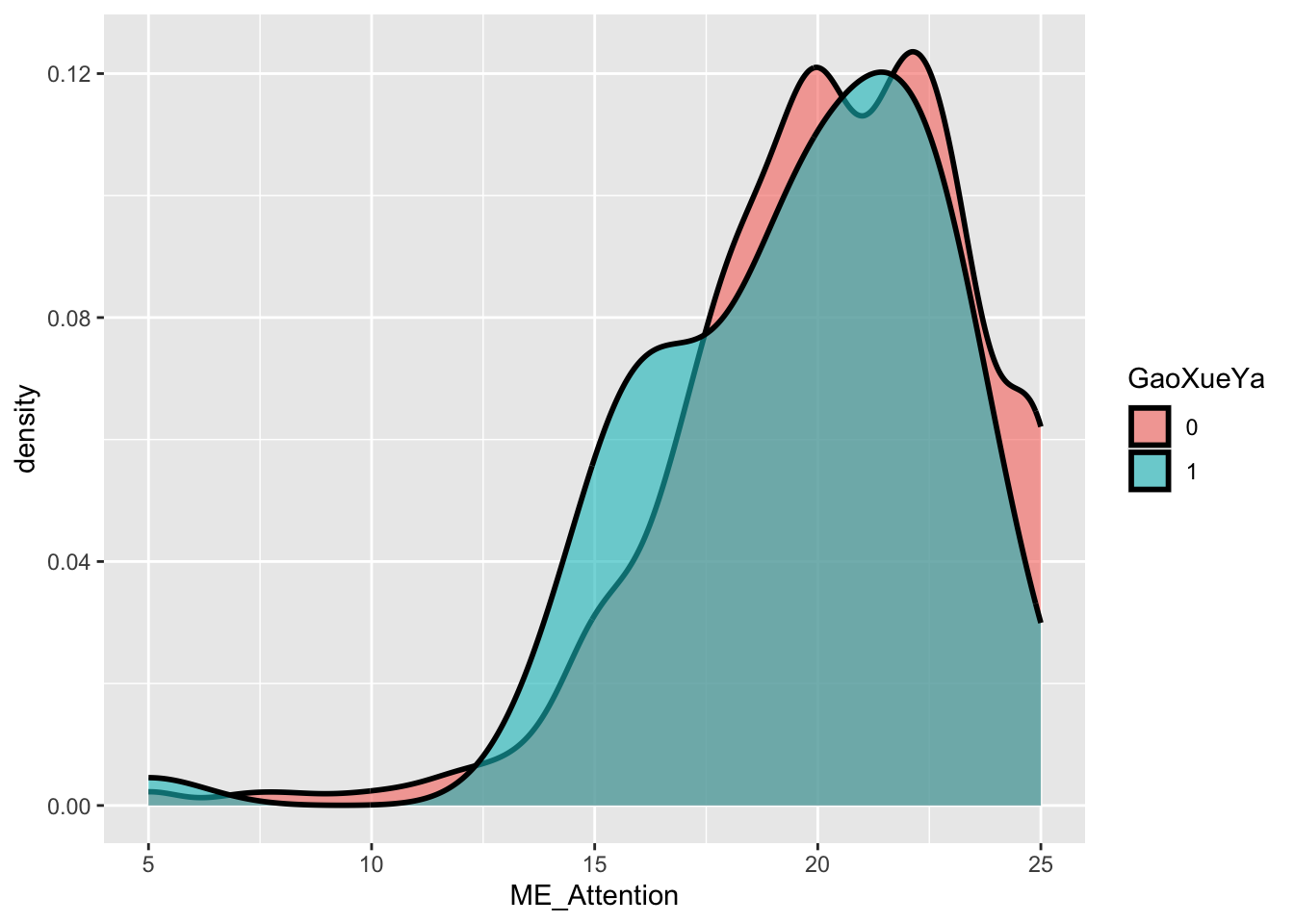
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_Attention, color = GaoXueTang)
) +
geom_density(linewidth = 1)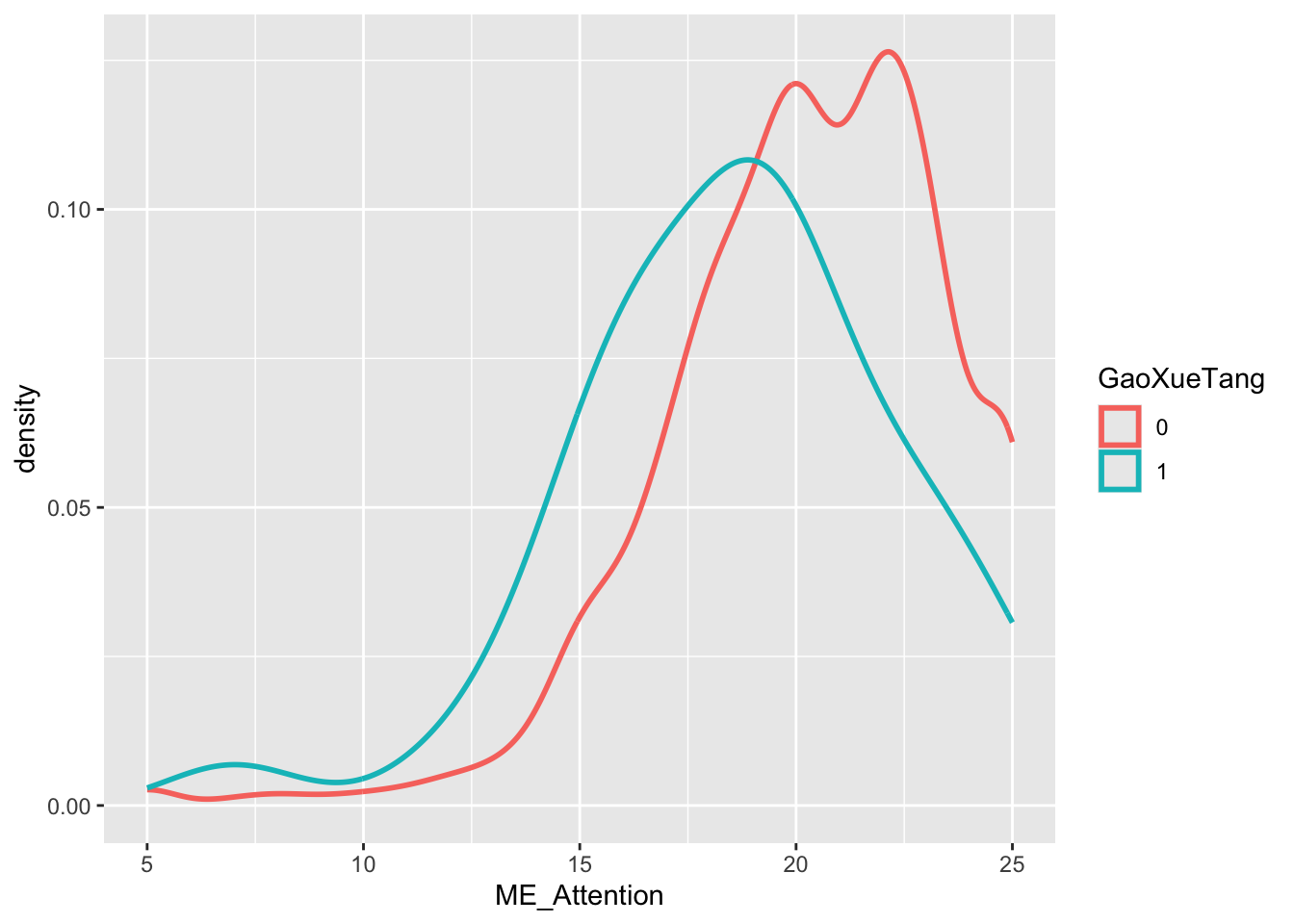
Interpretation: 非高血糖患者(红线:0)的ME_ Attention 在高分分数区域(》20)的占比显著高于高血糖患者。
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_Attention, color = XueZhiYiChang)
) +
geom_density(linewidth = 1)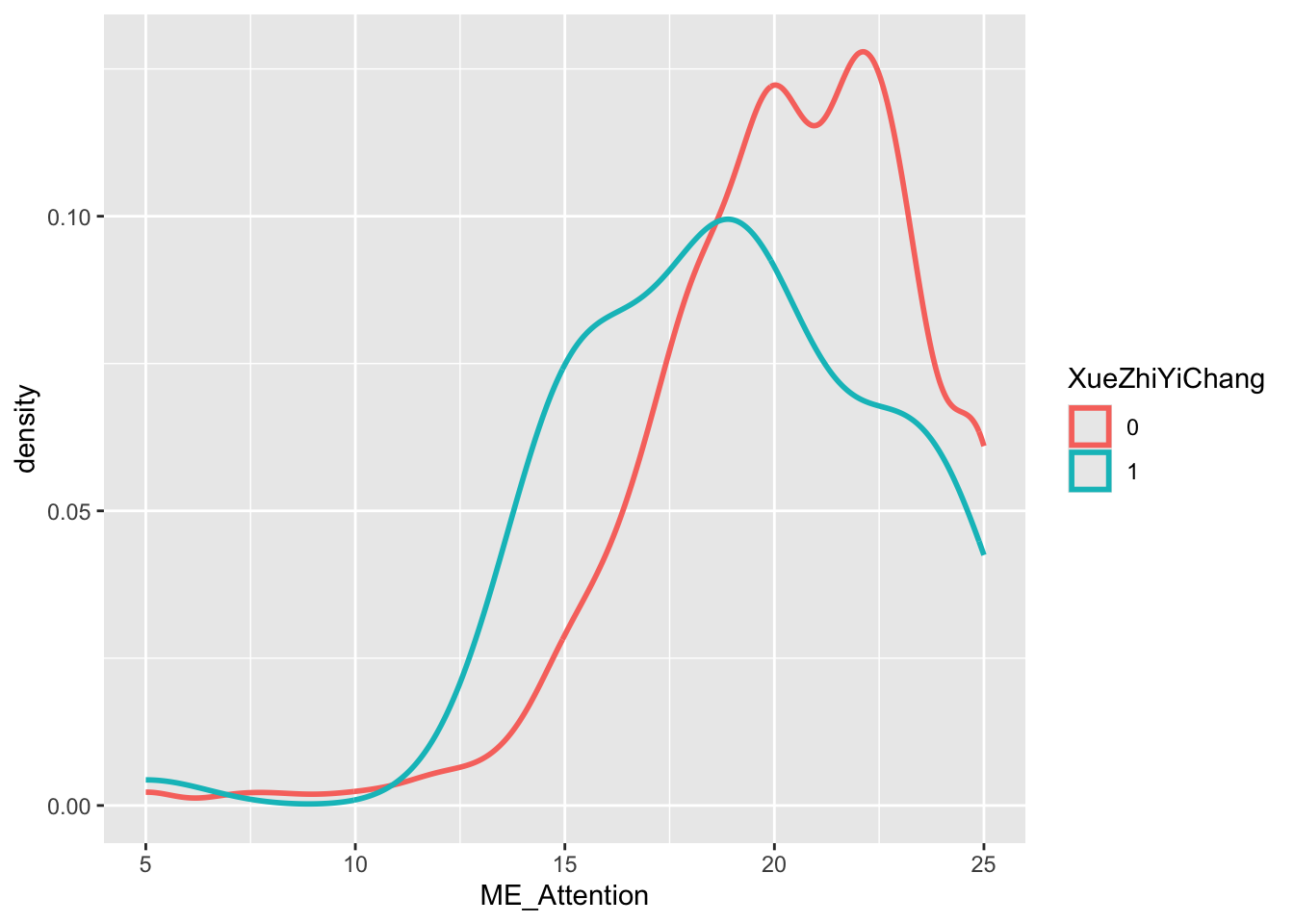
ME 2nd 指标 density: x = ME_New_Awareness, color = GaoXueYa
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_New_Awareness, color = GaoXueYa)
) +
geom_density(linewidth = 1)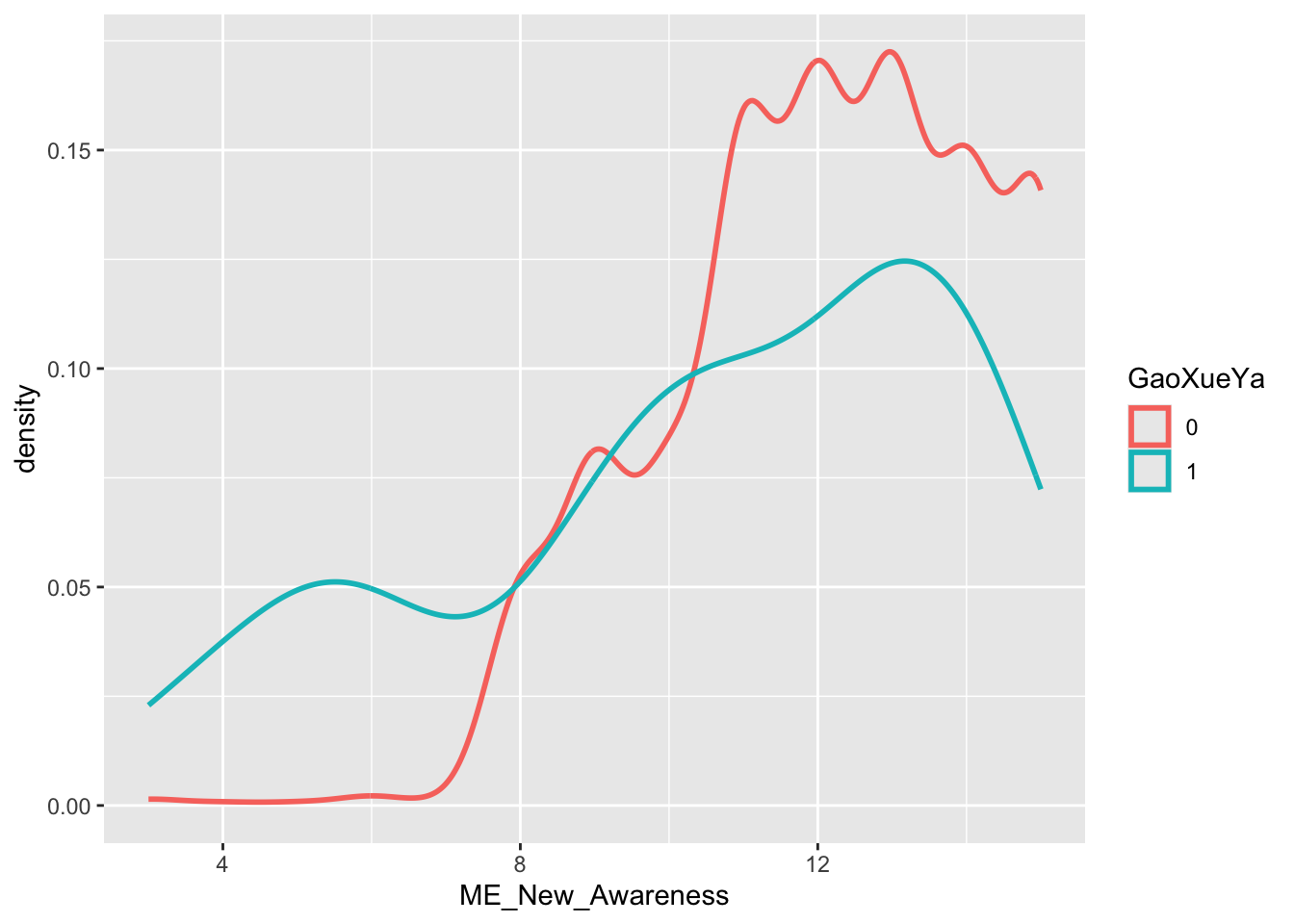
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_New_Awareness, fill = GaoXueYa)
) +
geom_density(linewidth = 1, alpha = 0.6)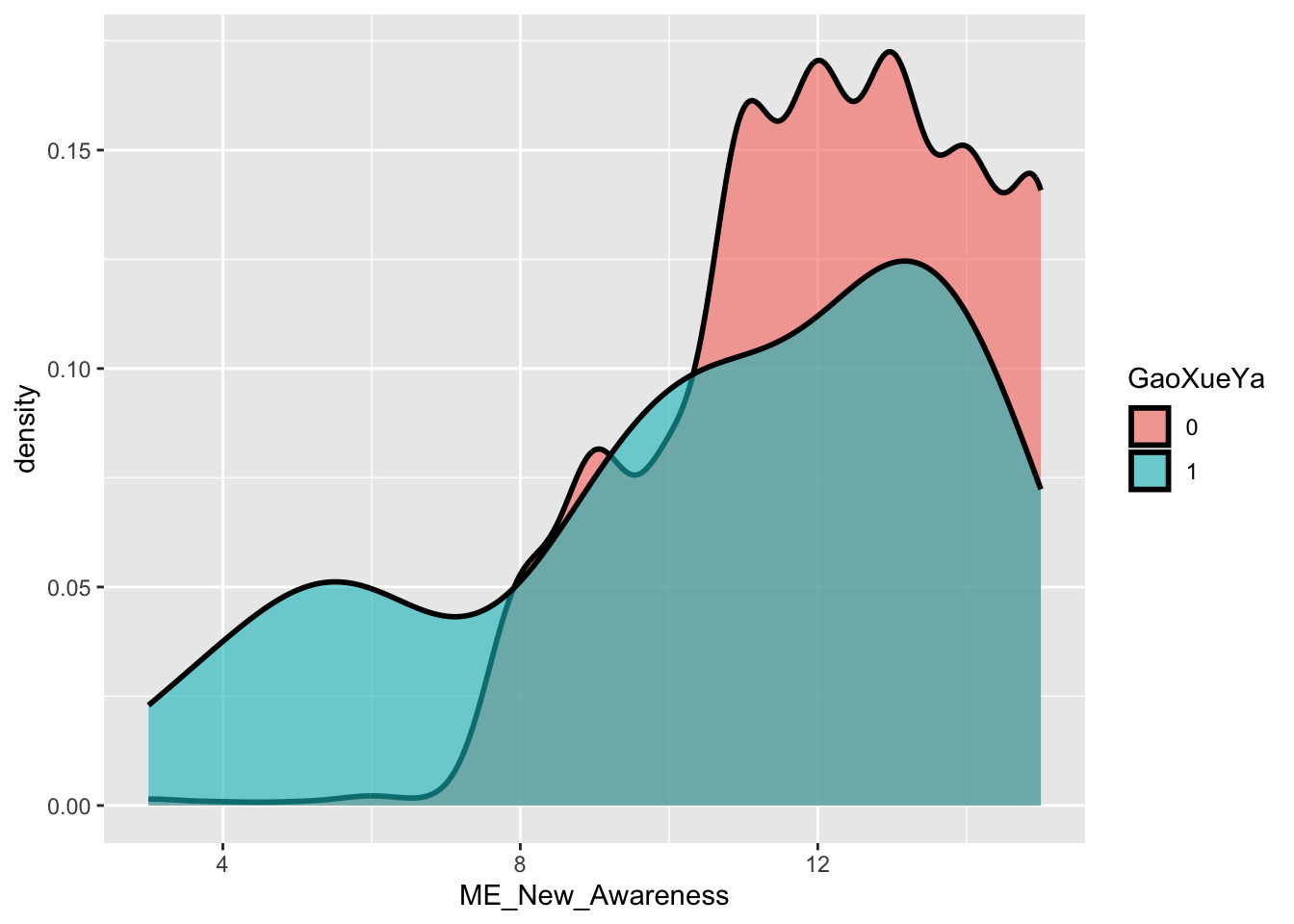
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_New_Awareness, color = GaoXueTang)
) +
geom_density(linewidth = 1)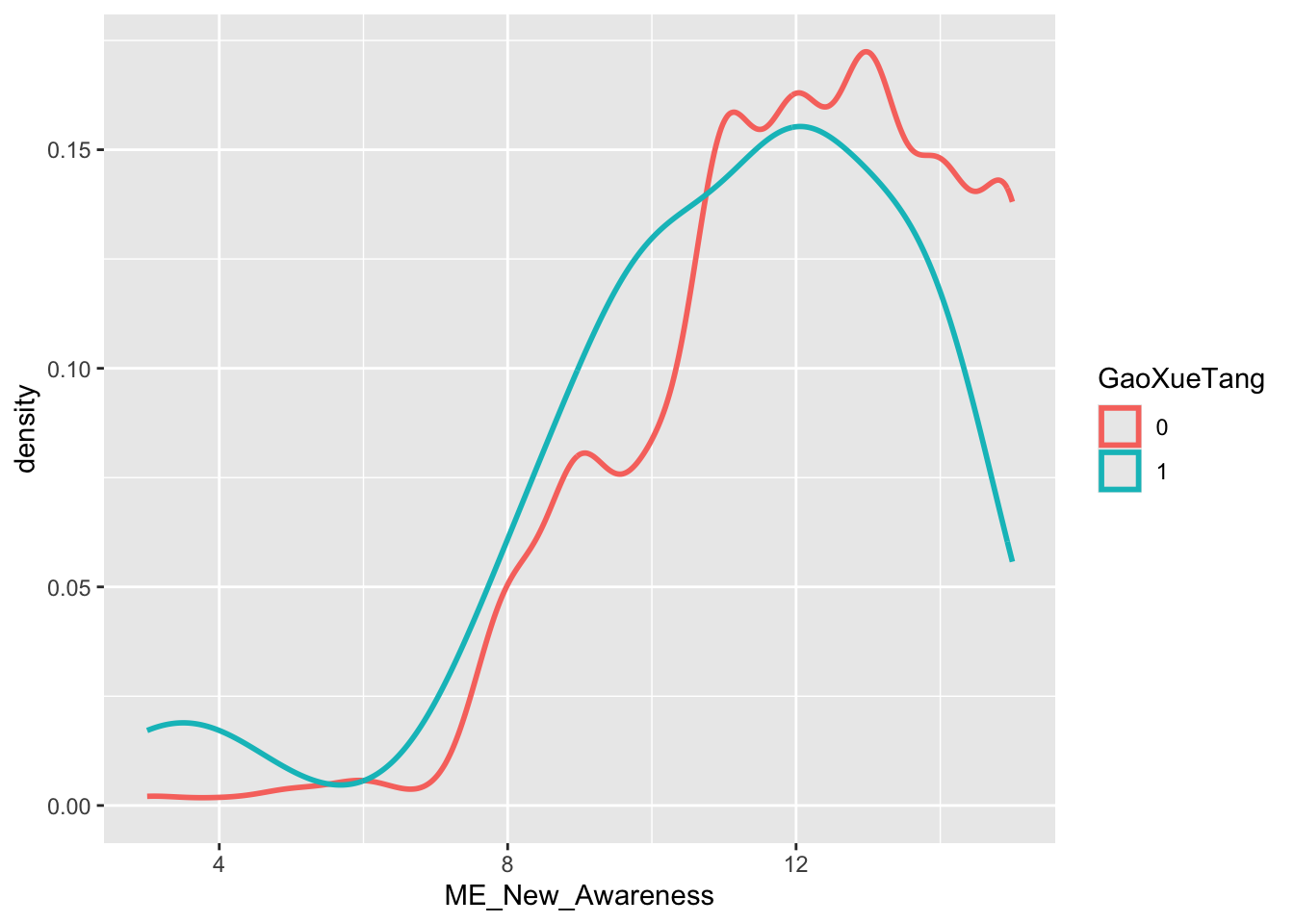
Interpretation: 非高血糖患者(红线:0)的ME_ Attention 在高分分数区域(》20)的占比显著高于高血糖患者。
ggplot(data = Raw_clean_modify,
mapping = aes(x = ME_New_Awareness, color = XueZhiYiChang)
) +
geom_density(linewidth = 1)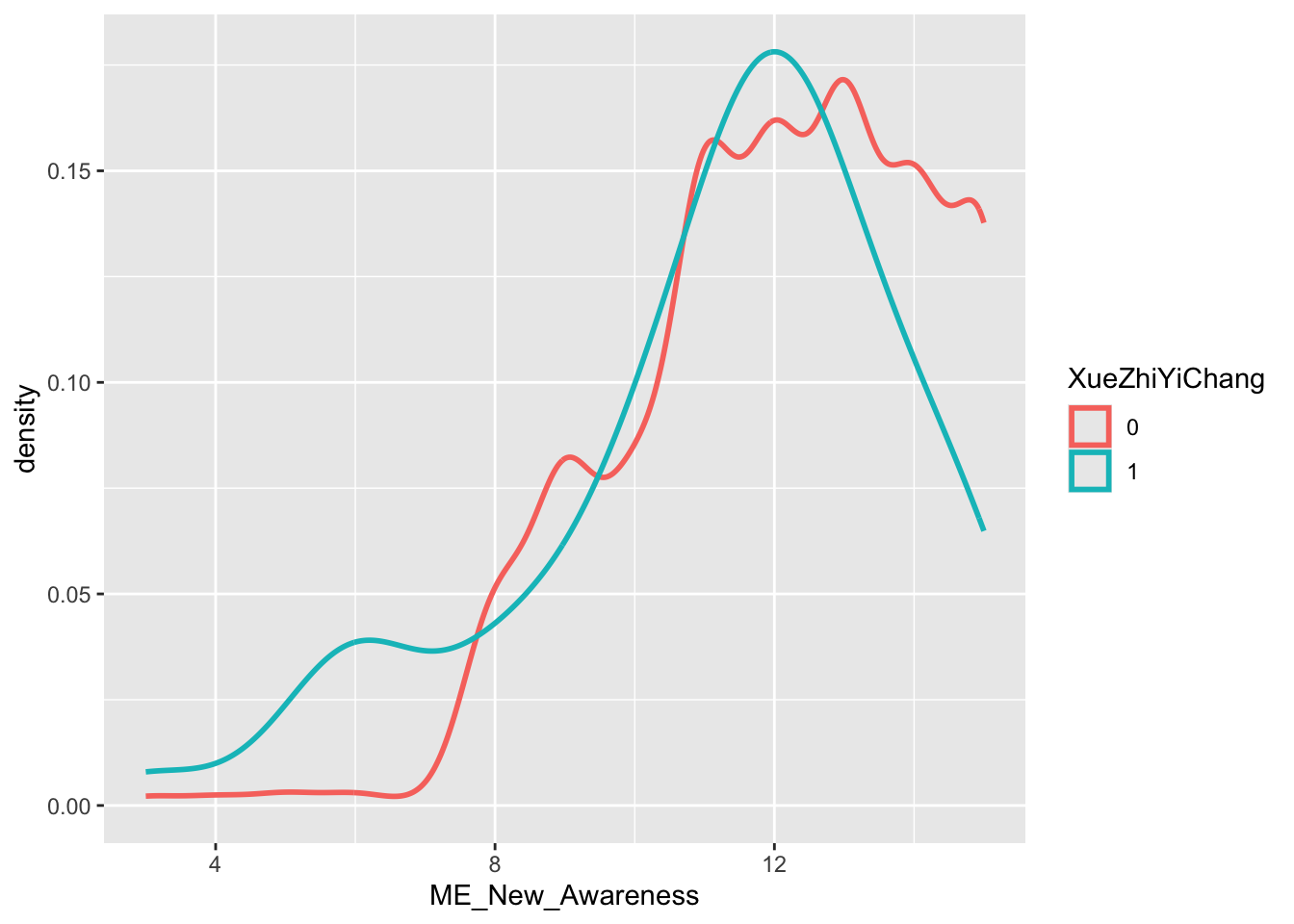
9.0.2 2 categorical variables
高血压 性别. 2 categorical variables
adjust Y-axis: position = “fill” to better observe the distribution/proportion of the categorical variables of interest.
ggplot(data = Raw_clean_modify,
mapping = aes(x = GaoXueYa)
) +
geom_bar(mapping = aes(fill = Gender),
position = "fill")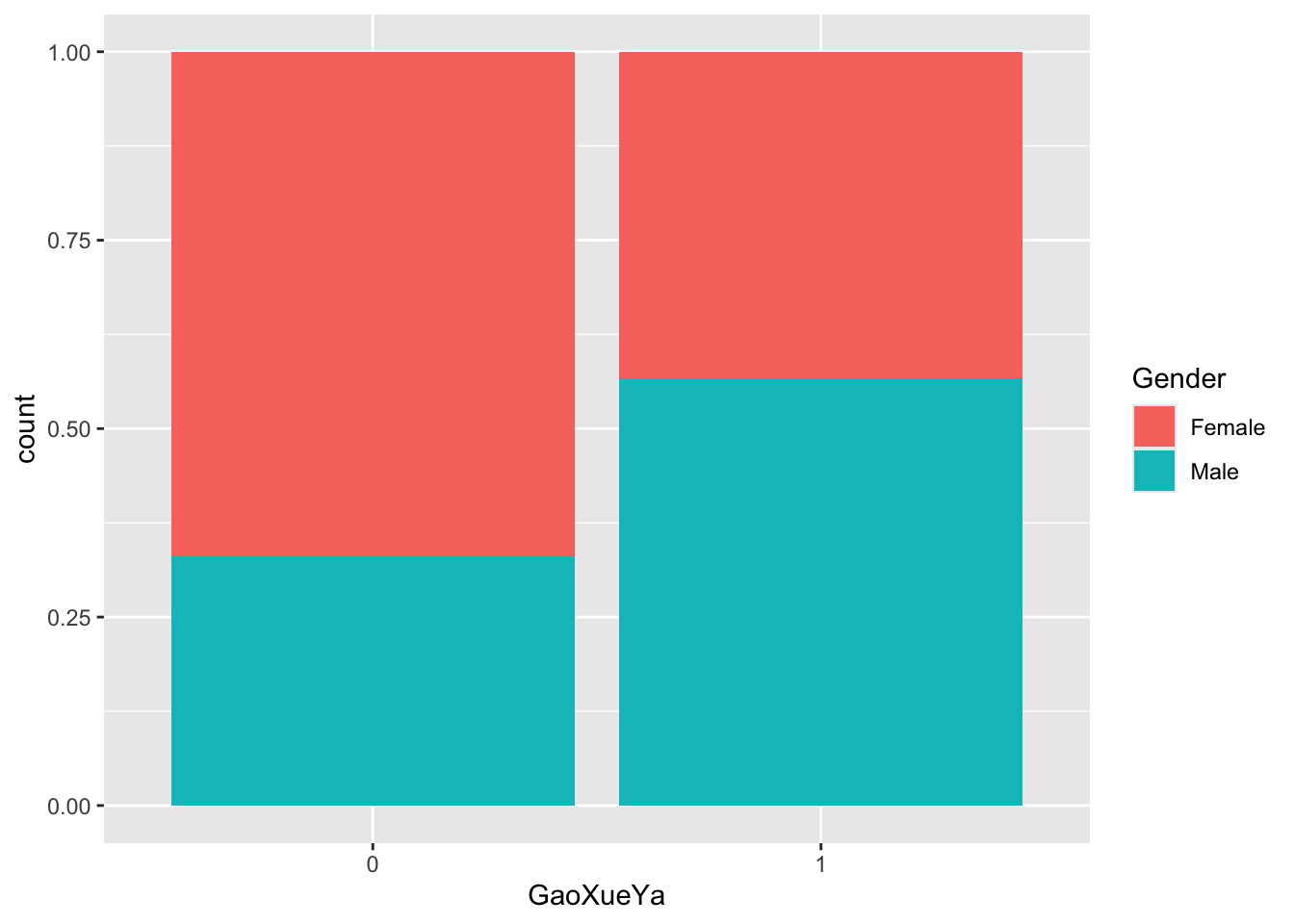
# A tibble: 2 × 2
Gender ME_Attention_mean
<fct> <dbl>
1 Female 20.2
2 Male 20.1#gwalkr(Raw_clean_modify)9.1 变量间关系探索
9.1.1 Heatmap
在数据清洁时,指标已经正确调成 factor 了,为了求协方差矩阵,data_lifestyle中指标回调成数值。 mutate_at(c('Monthly_Income','Exercise','Sleeping','Drinking','Smoking'),as.numeric)
9.2 A. 「全」Age + 生活方式变量 + ME得分
data_lifestyle_ME <-
Raw_clean_modify |>
select(Age,Monthly_Income,Exercise,Drinking,Smoking,
ME_Attention,ME_SatietyCue,ME_New_Awareness,
ME_New_Distraction) |>
mutate_at(c('Monthly_Income','Exercise','Drinking','Smoking',
'ME_Attention','ME_SatietyCue','ME_New_Awareness',
'ME_New_Distraction'), as.numeric)# Plotting the correlation heatmap
ggplot(melted, aes(Var1, Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white", midpoint = 0) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
labs(title = "Correlation Heatmap")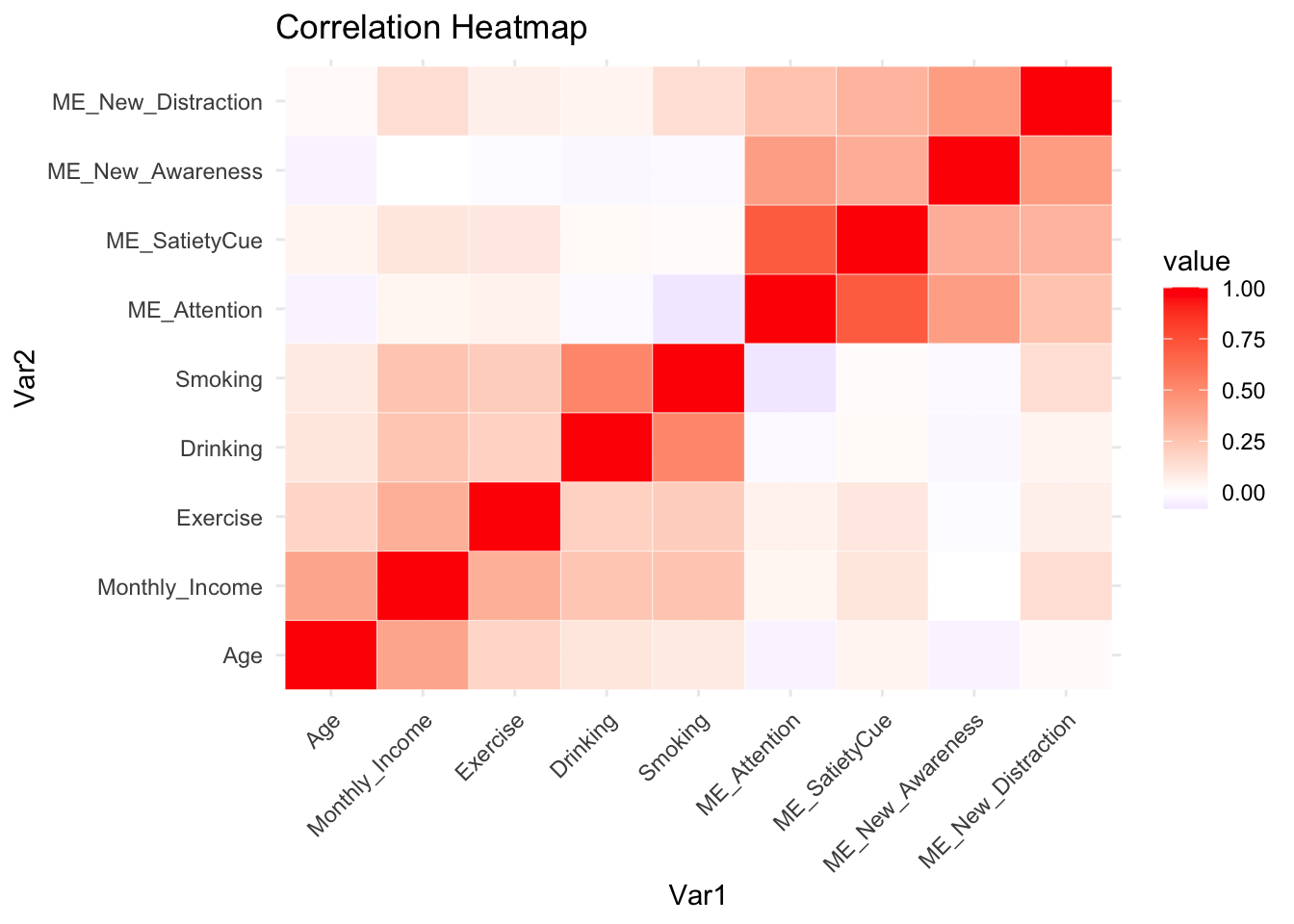
9.3 线性回归! ME scales 作为响应变量
9.3.1 「薛雨晴」 生活方式分类变量太碎,分成2类?再看回归结果。因为本来问题也主观,分成这么细也不会帮助解释
model1 <- lm(ME_Attention ~ GaoXueYa + Age + Monthly_Income, data = Raw_clean_modify) model1 |> get_regression_table()# A tibble: 6 × 7
term estimate std_error statistic p_value lower_ci upper_ci
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 intercept 20.5 0.302 68.0 0 19.9 21.1
2 GaoXueYa: 1 -0.574 0.421 -1.36 0.172 -1.4 0.251
3 Age -0.02 0.011 -1.78 0.076 -0.042 0.002
4 Monthly_Income: 2 0.158 0.245 0.645 0.519 -0.322 0.638
5 Monthly_Income: 3 0.531 0.252 2.11 0.035 0.037 1.02
6 Monthly_Income: 4 0.612 0.442 1.38 0.167 -0.256 1.48 model1 |> get_regression_summaries()# A tibble: 1 × 9
r_squared adj_r_squared mse rmse sigma statistic p_value df nobs
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.007 0.004 10.7 3.27 3.28 1.98 0.079 5 13359.3.2 easyStats:: 模型选择
(model1_sel <-
model1 |>
select_parameters() |> summary()
)
Call:
lm(formula = ME_Attention ~ GaoXueYa, data = Raw_clean_modify)
Residuals:
Min 1Q Median 3Q Max
-15.1956 -2.1956 -0.1956 2.8044 5.4925
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.19558 0.09217 219.104 <2e-16 ***
GaoXueYa1 -0.68812 0.41144 -1.672 0.0947 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.282 on 1333 degrees of freedom
Multiple R-squared: 0.002094, Adjusted R-squared: 0.001345
F-statistic: 2.797 on 1 and 1333 DF, p-value: 0.09467原回归 表现
#report(model1)
model_performance(model1)# Indices of model performance
AIC | AICc | BIC | R2 | R2 (adj.) | RMSE | Sigma
------------------------------------------------------------------
6966.806 | 6966.890 | 7003.183 | 0.007 | 0.004 | 3.271 | 3.278